データ分析人材育成支援
データ活用が企業成長の鍵となる今、分析スキルを持つ人材の育成と、強力なデータ分析チームの構築は欠かせません。
AITでは、実践的な教育メニューを通じて、現場で即戦力となる人材の育成を支援します。統計や機械学習の基礎から、ビジネス課題に直結する分析手法まで、段階的に学べるプログラムを提供。さらに、チーム全体のスキル底上げや、分析文化の定着を目指した組織支援も行っています。

データ分析人材育成支援メニュー

操作トレーニング

分析ツールの基本操作トレーニングになります。
対象分析ツール:
IBM SPSS,Tableau,Python
各分析ツールの基本的な操作方法を学習頂くことを目標とします。

データ分析
初級・中級トレーニング

データ分析に必要となる基礎知識<講義>と、サンプルデータを使った<演習>とで構成されるトレーニングになります。
基本的な分析のプロセスに必要となる知識を学習いただくことを目標とします。

データ分析
実践トレーニング

お客様の分析テーマ、データを使って、分析プロセスを実施いただきます。
本トレーニングを通じて、取扱いデータの加工方法や統計手法を使った分析モデルの作成、分析精度を高めるための実践スキルをOJT形式で学習頂くことを目標とします。
※お客様にご準備頂くもの:分析ツール導入済受講者用PC(各メニュー共通)
各支援内容

操作トレーニング
SPSS
SPSS Modelerを初めて使うお客様向けに、基本操作から分析に必要となるデータ加工、及び、分析モデルの作成方法を学習頂く為のハンズオン形式の操作トレーニングになります。
-
Step 1 基本操作編
- IBM SPSS Modelerの基本操作
- データ加工基礎
-
Step 2 データ加工編
- IBM SPSS Modelerの中級操作
- データ加工応用
-
Step 3 モデリング編
- 分析モデル作成方法
- モデル理解と読み取り方の習得
Tableau
Tableauを初めて使うお客様向けに、Tableau Desktopの基本的な操作方法と特徴を理解し、データの可視化・分析方法を学習頂く為のハンズオン形式の操作トレーニングになります。
トレーニング終了時には、以下のゴールを達成することを目指します。
- Tableau Desktopの基本的な使い方を理解する
- 代表的な可視化手法(棒グラフ、折れ線グラフ、バブルチャートなど)を活用できる
- 自身の業務におけるTableauの活用イメージを持てるようになる
Python
データ分析に必要となるPythonのハンズオン形式のトレーニングを、以下の3つのコースでご提供します。
-
Step 1 初級編Pythonの基本構文を学び、サンプルデータの簡単な加工と結果の出力ができるようにことを目標とした内容
-
Step 2 データ加工編データ分析ライブラリ「Pandas」を使えるようになることを目標とした内容
「Pandas」を利用することにより、大量データの読み込み・加工・出力が簡単に出来るようになります。 -
Step 3 分析編データ解析・機械学習のライブラリを利用して、分析モデルを作成することを目標とした内容

データ分析初級・中級トレーニング

データ分析に必要となる基礎知識<講義>と、サンプルデータを使った<演習>とで構成される3~4日間の集合形式トレーニングになります。
目的
-
データ分析初級 <分析モデル編>データ分析の概念とビジネスで使われる代表的な分析モデルの種類を学習
-
データ分析中級 <データ加工編>データの準備からモデルチューニングに必要となるデータ加工までを学習
-
データ分析中級 <モデリング編>分析モデルのチューニングとビジネス評価・展開までを学習
アジェンダ
※基本的なアジェンダになります。内容のカスタマイズも可能です。
※演習で利用する分析ツールは、IBM SPSS Modelerが前提となります。
- データ分析初級<分析モデル編>(1日:10時~17時)
-
1.ビジネスに活用できるデータの取得
- 分析の内容と目的の明確化
- 分析対象のデータの準備
- 分析プロジェクトの成功要因
- データ活用のPDCAサイクル(CRISP-DM)
-
2.ターゲティング - 決定木分析とは
- 分析事例:反応予測
- 可視化
- 決定木分析とは
-
3.レコメンデーション ー アソシエーション分析とは
- 分析事例:レコメンデーション
- アソシエーション分析とは
-
4.顧客分類 ー クラスター分析とは
- 分析事例:顧客分類
- クラスター分析とは
- データ分析中級・データの準備/モデルチューニング<データ加工編>(1日10時~17時)
-
1.データの準備
- 分析対象定義、検出
- データのクリーニング
- 複数ソースの結合
- 特徴量作成
- フォーマット(1行1ID)化
-
2.モデル・チューニング<データ加工①>
- モデル・チューニングとは
- 初期データ収集
- データ検査
- 特徴量作成
-
3.モデル・チューニング<データ加工②>
- 特徴量作成
- データ分析中級・データの準備/モデルチューニング<モデルチューニング/評価展開編> (1日10時~17時)
-
1.モデル・チューニング<モデリング①>
-
最適モデル検出(数値予測)
- 線形回帰分析とは
-
最適モデル検出(判別予測)
- ロジスティック回帰とは
- ニューラルネットワークとは
-
最適モデル検出(数値予測)
-
2.モデル・チューニング<モデリング②>
-
最適モデル検出(数値・判別予測)
- アンサンブル学習とは
-
最適モデル検出(数値・判別予測)
-
3.モデル評価
-
モデル評価
- 正答率、適合率、再現率
- ゲインチャート、ROC曲線、AUC
-
モデル評価
-
4.モデルのビジネス評価・展開
-
ビジネス評価
- 絶対値評価
- プロフィット、レスポンスチャート
- 展開(予測スコア作成)
-
ビジネス評価

データ分析実践トレーニング
図「CRISP-DM」に沿って分析プロセスを実施いただきます。
「CRISP-DM(※)」は、データ分析プロジェクトを成功へ導く為の典型的な流れと作業の説明が含まれるデータマイニングの標準化プロセスになります。
本プロセスを用いて、取扱いデータ毎の加工方法や統計手法を使った分析モデルの作成、分析精度を高めるための実践スキルをOJT形式で学習頂くことを目標とします。
※「CRISP-DM」CRoss Industry Standard Process for Data Mining
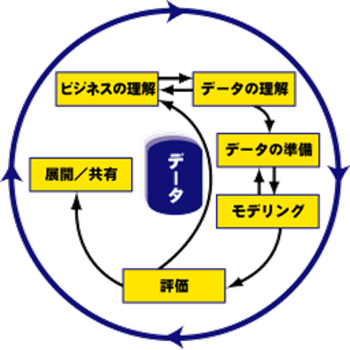
業種を超えたデータマイニングの標準化メソドロジー
CRISP-DMでは、データマイニングのプロセスとして6つのフェーズで構成
-
1.ビジネスの理解
ビジネス上の問題点をはっきりと理解し、プロジェクト目標を設定する。
-
2.データの理解
散在するデータの所在を確認、本当に使用できるかどうか内容を把握。
-
3.データの準備
分析できる状態にデータを加工。
-
4.モデリング
分析に適したモデリング手法を選択し、データを分析。
-
5.評価
プロジェクト目標を達成するために十分なモデルであるかどうかをビジネスの観点から評価。
-
6.展開/共有
プロジェクトで得られた結果を意思決定者が使用できるようにし、具体的なアクションをおこす。
実施例
※基本的な実施例になります。内容のカスタマイズも可能です。
※分析ツールは、IBM SPSS Modelerが前提となります。
- データ分析実践トレーニング:アドバイザリーサービス
-
目的分析プロジェクトの早期立ち上げを目指して、データ分析のプロセスに基づき、ツールの操作、プロジェクトに必要なデータ加工や分析手法をポイントを押さえて学習
-
実施方法
- 期間:3ヶ月
- 1~2週間に1回程度の3時間のアドバイザリーセッションを実施
- 1回のアドバイザリーサービスご提供時間は3時間
- 各セッション間(1~2週間)に自習テーマを課すことで、セッションで習得した知識を効率よく復習
研修ステップ

操作トレーニング

データ分析
初級・中級トレーニング

データ分析
実践トレーニング
お気軽にご相談下さい

関連サイトのご案内
分析支援サービス
分析プロジェクトの検討段階から、データ準備の支援、モデル開発、ビジネス活用、また人材育成までをトータルにご支援。
Pythonトレーニング
データ分析の為のPythonプログラミングトレーニング